您的购物车目前是空的!
神经网络概述
分类 神经网络基础

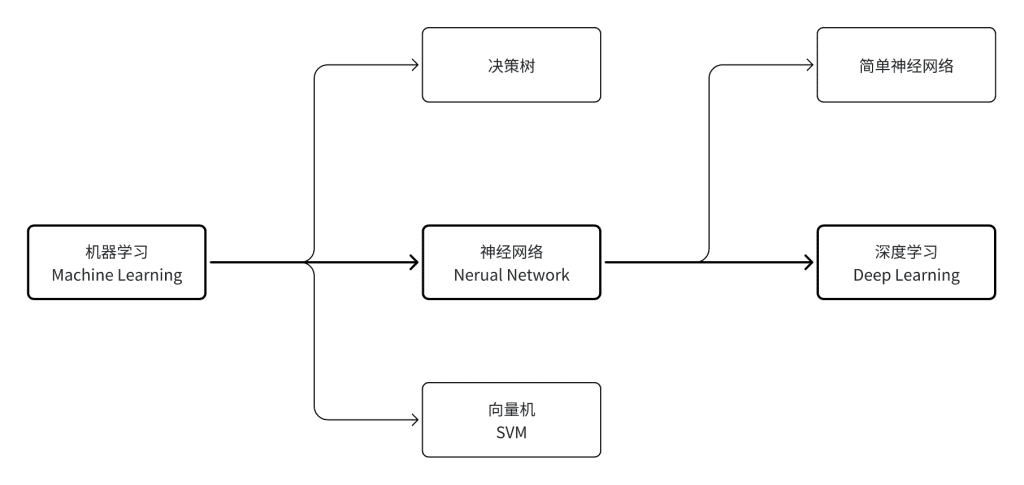
1. 机器学习(Machine Learning)
机器学习是通过数据自动学习规律,并利用这些规律对未知数据做出预测的计算机技术。- 相比传统的程序设计,
机器学习不需要手动编写规则,而是通过优化算法从数据中提取模式来达成目的。 - 从
1950年起出现众多机器学习方法,包括:决策树、向量机(SVM)、K近邻(KNN)、神经网络等等。
1.1 神经网络(Neural Network)
- 随着
机器学习的发展,自2010年后,神经网络已成为现代机器学习的核心主线,目前超过 90% 的应用场景基于神经网络实现。 - 神经网络是一种由节点和连接构成的模型,具备可组合、可嵌套、支持任意复杂非线性建模的能力。
- 随着 GPU 等算力的大幅提升,以及大规模训练数据的积累,神经网络迅速崛起,成为主流机器学习方法。
1.2 深度学习(Deep Learning)
- 深度学习是现代
深层神经网络的统称,用以区别早期结构简单的神经网络(如感知器、多层感知机等)。它强调通过多层非线性变换自动提取复杂特征。 - 深度学习属于机器学习的子集,也属于神经网络范畴,三者的关系可表述为:
2. 学习范式(Learning Paradigms)
- 根据
机器学习对数据标签的使用方式及其优化策略,可将其划分为以下几种主要的学习范式: - 不论使用哪种机器学习方式,都可能会涉及不同的学习范式,主要依据诗句的使用和学习来划分。如回归任务、分类任务等神经网络会基于监督学习。自然语言处理(NLP)涉及非监督学习。
3. 神经网络结构
3.1 全连接神经网络(Fully Connected Neural Network)
- 神经网络中最基础的一种结构,自诞生以来不断演化,不仅构成了后续复杂网络的
原型,也在实践中验证了许多重要的数学理论。 - 在发展过程中,这类网络有多个常见称呼,反映了不同角度下的理解与应用背景。实际应用中虽然名称不同,但是表示同一个神经网络结构。
3.2 卷积神经网络(Convolutional Neural Network, CNN)
- 卷积神经网络是深度学习中处理图像和空间数据最核心的结构之一,最早由
Yann LeCun等人在 1980–1990 年代提出,并应用于手写数字识别任务。随着 AlexNet 在 2012 年 ImageNet 大赛中的突破性表现,CNN成为计算机视觉领域的主流架构。 - 相比于全连接神经网络,
CNN通过引入卷积层与池化层,实现了:- 局部感知:每个神经元只连接输入的一小部分区域,捕捉局部特征;
- 权重共享:同一个卷积核应用于整个输入,极大减少参数数量;
- 空间结构保留:输入的空间排列在中间层得以保留,适合处理图像、语音、视频等二维/三维结构数据。
CNN是当前图像分类、目标检测、人脸识别等视觉任务的主力模型,其经典架构包括LeNet、AlexNet、VGG、ResNet、Inception等。
3.3 循环神经网络(Recurrent Neural Network, RNN)
- 循环神经网络是一类专门用于处理序列数据的神经网络结构,广泛应用于
自然语言处理、语音识别、时间序列预测等任务。 - 与前馈神经网络不同,
RNN引入了“循环连接”,允许网络在时间维度上传递状态,实现对历史信息的记忆和建模。这使得RNN能够处理长度可变的输入序列,是早期解决时序建模问题的核心结构。 RNN在发展过程中出现了多个变种,以解决原始结构中存在的梯度消失和长程依赖问题:- 长短期记忆网络(
LSTM):引入门控机制,能够捕捉长期依赖; - 门控循环单元(
GRU):结构更简洁,训练更高效,性能与LSTM接近; - 双向
RNN:同时考虑过去与未来的上下文,提升理解能力。
- 长短期记忆网络(
- 虽然近年来
RNN在NLP中逐渐被Transformer架构取代,但在某些轻量场景和低资源设备中仍具有实际应用价值。
3.4 Transformer 网络(Transformer)
Transformer是一种基于自注意力机制(Self-Attention)的神经网络架构,由Vaswani等人于 2017 年提出,首次完全舍弃了传统的循环结构,在自然语言处理任务中取得突破性成果。- 与
RNN不同,Transformer允许模型在每一层直接建立任意位置之间的全局依赖关系,从而显著提升了训练并行性和长距离建模能力。 Transformer架构的关键组成包括:- 多头自注意力机制(
Multi-Head Attention):从多个角度捕捉不同位置之间的关联; - 位置编码(
Positional Encoding):在无序输入中引入顺序信息; - 前馈网络 + 残差连接 +
LayerNorm:增强特征变换能力与稳定性。
- 多头自注意力机制(
Transformer已逐渐成为统一的通用神经网络框架,广泛应用于文本(BERT、GPT)、图像(ViT)、语音、视频、多模态生成等领域,是当今大模型发展的核心基石。- 代表性模型包括:
BERT:用于理解型任务(分类、问答)GPT系列:用于生成型任务(对话、写作、代码生成)ViT:将 Transformer 应用于图像领域Stable Diffusion/DALL·E:作为图像生成模型中的文本编码器
3.5 扩散模型(Diffusion Model)
- 扩散模型是一类基于逐步
加噪与去噪过程的概率生成模型,最早由学术界在 2015 年提出,近年来因在图像生成任务中的卓越表现而成为主流结构之一。 - 其核心思想是:
- 正向过程:将训练图像逐步加入高斯噪声,最终变成纯噪声;
- 反向过程:训练一个神经网络,学习如何一步步将噪声“还原”为清晰图像。
- 扩散模型目前已广泛应用于图像生成、图像编辑、图像修复、语音合成、视频生成等领域。主流结构包
DDPM:经典去噪扩散概率模型(Denoising Diffusion Probabilistic Model)Latent Diffusion:将扩散过程转移至 VAE 的潜空间,提升生成效率Stable Diffusion:结合UNet、CLIP和Latent Diffusion,成为开源图像生成代表作
- 与
Transformer结合后,扩散模型已成为文生图、图文混合创作等AIGC场景的技术核心。
Table Of Contents
发表回复